多模态 AI 的边界正在不断拓展一个能够无缝处理多种数据形式并进行生成与理解的统一模型始终是人工智能研究的核心目标。Lumina-DiMOO 的出现标志着这一目标又向前迈出了重要一步它以独特的技术路径描绘了未来的多模态交互图景。
Lumina-DiMOO 揭秘
Lumina-DiMOO 由 Alpha VLLM 团队联合上海人工智能实验室 上海交通大学等顶尖机构共同开发它并非简单的拼接而是基于四个核心创新构建了一个全能型多模态模型。
统一离散扩散架构
与传统模型不同 Lumina-DiMOO 采用了一种完全离散的扩散建模方法来处理不同模态的输入输出。这意味着所有数据无论文本图像还是其他形式都被统一到一个框架下进行处理这在理论上简化了多模态学习的复杂性并可能带来更一致的性能。这种设计思路在同类统一模型中独树一帜体现了前瞻性。
全能多模态能力
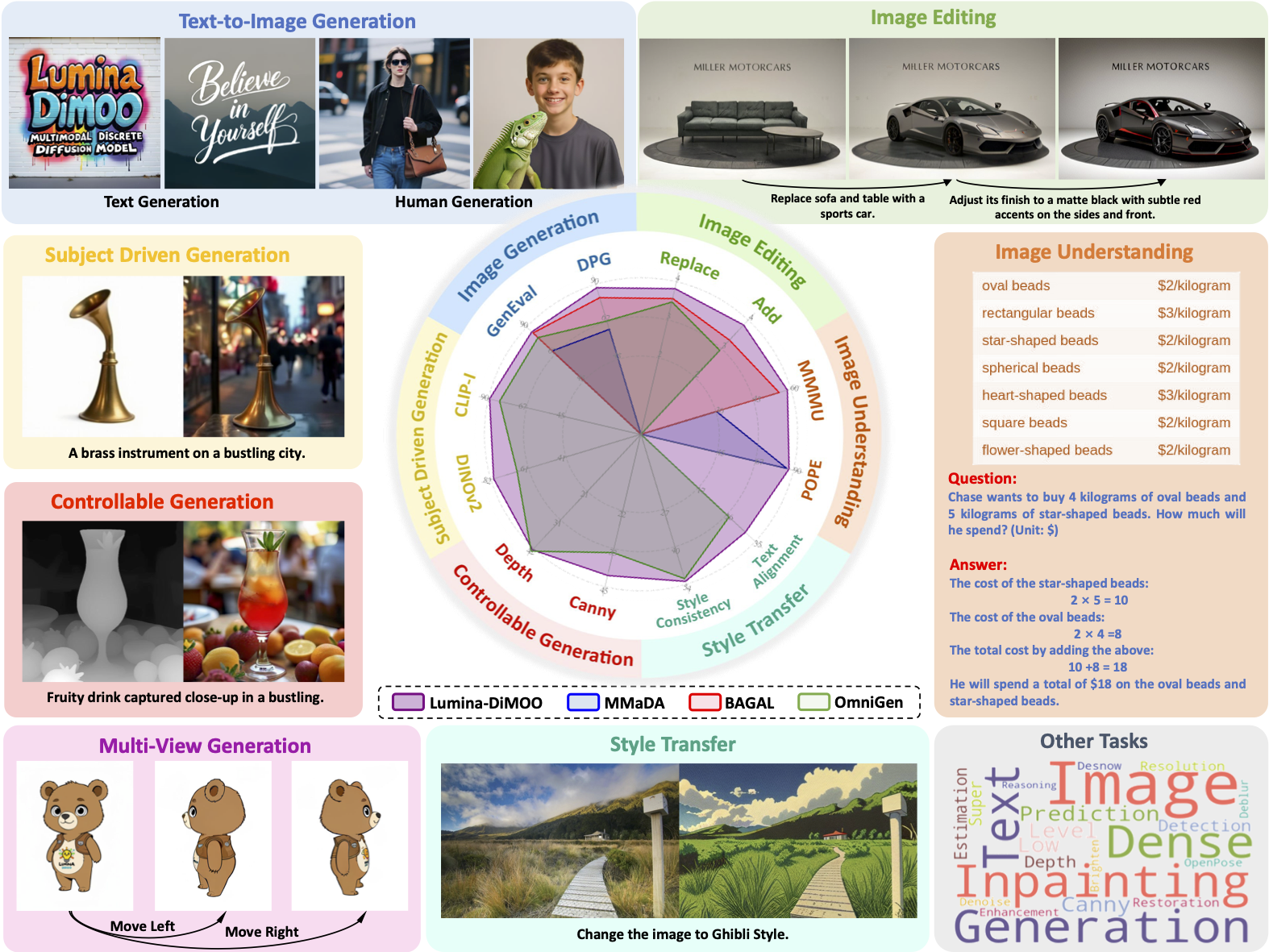
Lumina-DiMOO 展示了惊人的多模态任务覆盖广度。它不仅支持高质量的文本生成图像包括任意分辨率的图像生成能力还擅长图像到图像的转换例如图像编辑 主题驱动生成以及图像修复等。此外其在图像理解方面的表现也达到了先进水平。这表明它能够无缝地在生成和理解任务之间切换是真正的“多面手”。
卓越采样效率
在速度方面 Lumina-DiMOO 也交出了亮眼的答卷。相较于以往的自回归或混合自回归扩散范式 Lumina-DiMOO 拥有显著的采样效率。
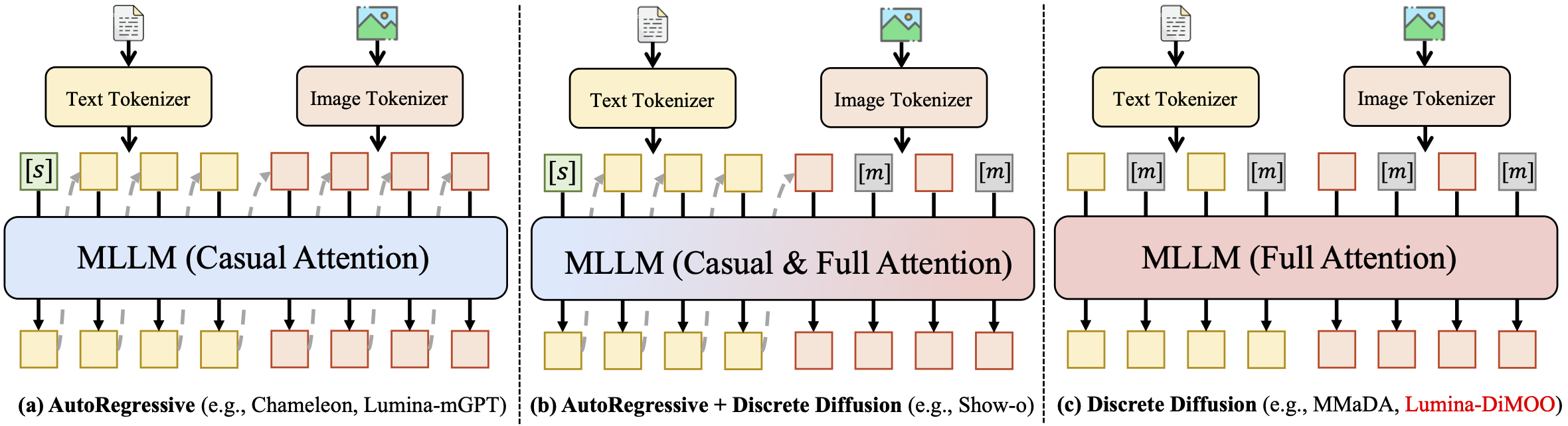
研究团队还为此设计了一种定制缓存方法进一步将采样速度提升了两倍。对于实际应用来说这意味着更快的响应速度和更低的计算成本。
性能新标杆
在多项基准测试中 Lumina-DiMOO 都取得了领先成果。无论是在 GenEval DPG OneIG-EN TIIF 还是图像到图像和图像理解的基准测试中它都超越了现有的开源统一多模态模型树立了新的行业标准。这充分证明了其技术的先进性和稳定性。
实际效果一览
通过一系列直观的对比结果可以看出 Lumina-DiMOO 在文本生成图像 图像编辑 可控生成 图像修复等任务中展现了出色的视觉质量与细节处理能力。
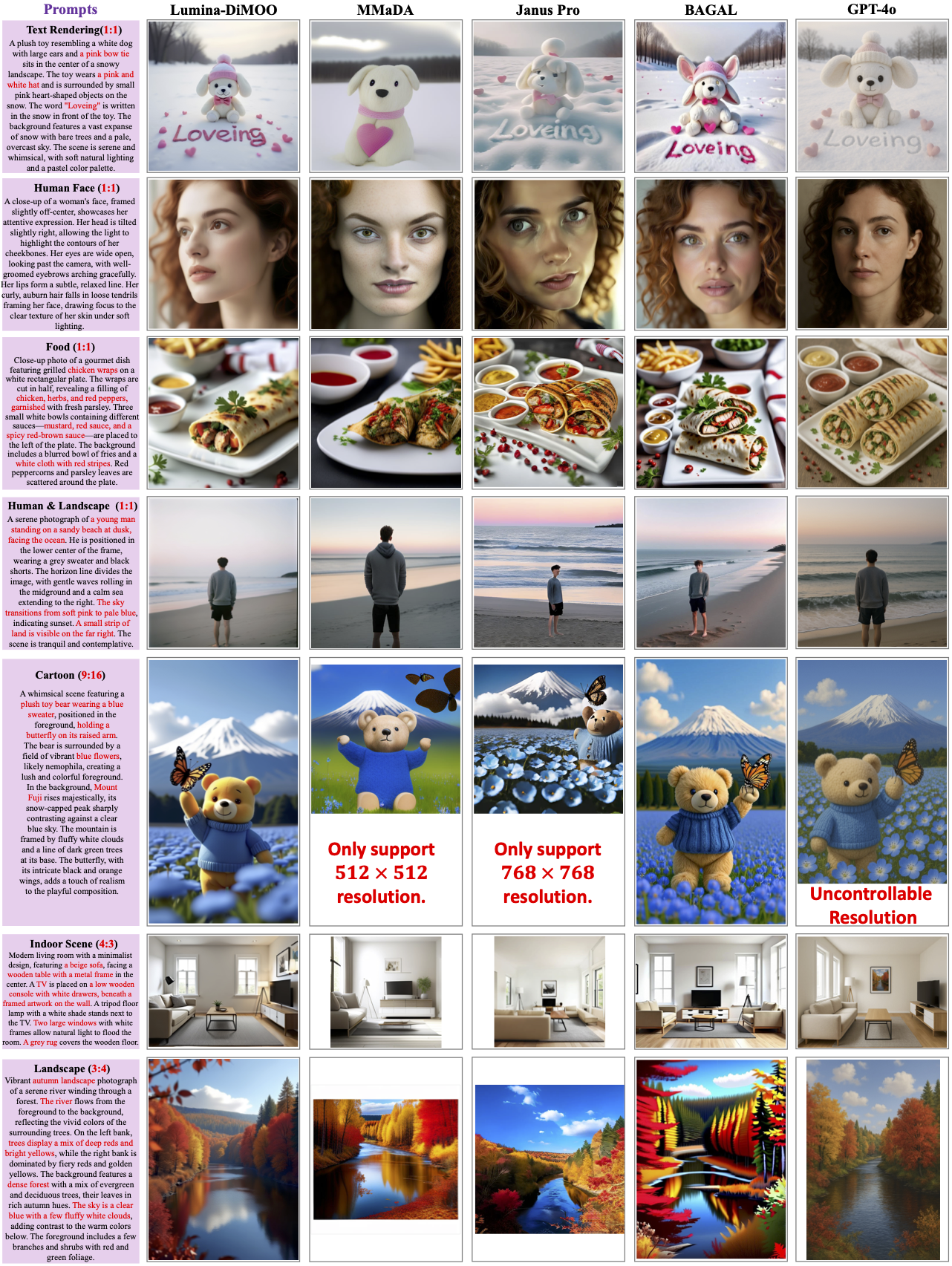
这些实际案例进一步验证了模型理论优势在实践中的落地。更多可视化效果可以在其项目页面查看。
核心团队背景
此项创新工作汇聚了多家知名机构的力量包括上海人工智能实验室 上海创新研究院 上海交通大学 南京大学 悉尼大学 香港中文大学以及清华大学。强大的科研背景为 Lumina-DiMOO 的突破性进展提供了坚实基础。
结语
Lumina-DiMOO 的问世不仅为多模态 AI 领域带来了新的技术范式更预示着一个更加统一 高效 智能的 AI 未来。对于追求前沿技术的 AI 爱好者来说这无疑是一个值得深入探索与关注的重要进展。其技术报告已发布在 arXiv 上代码也已在 GitHub 开源项目地址是 Alpha-VLLM/Lumina-DiMOO。更多详情和互动演示请访问其项目主页。synbol.github.io/Lumina-DiMOO。